Lesson07 リスト

数字や文字列が連なったデータ リストを学ぼう
- リスト
- リストの作り方
- リストの要素にアクセスする
- リストへの要素の追加と削除
- リストを保持する変数にリストを代入する
- リストをネストする
- 文字列からリストを作成する
これまでデータとは文字列であったり、数値であったりしました。Python には、この他にも様々なデータのタイプがあります。今回は、リストと呼ばれる数字や文字列が連なったデータについて学びます。
今使うソースコードはここからまとめてダウロードできます。 ダウンロードfile_download
前回の復習
前回は繰り返し処理を自動化する while 文を学びました。
前回出た重要キーワード
- while
- continue
- break
- インクリメント
- ループ変数:for ループや while の中で自動的に変化する変数。
- break:ループを抜けるときに使う命令
- continue:ループをスキップするときに使う命令
- インクリメント:ループ変数を増やすこと
1リスト
この章のキーワード
- リスト
- インデックス
- リストの要素
- リストの要素の変更
- リストへの要素の追加、append
- リストのリスト(リストのネスト)
1.1 リストの作り方
リストは変数がタンスになったような構造です。0 番目の引き出し、1 番目の引き出し、2 番目の引き出しという風にそれぞれの引き出しを使った複数のデータをセットできるデータ構造です。リストは普通、分かりやすい名前をつけた変数にセットします。次の例では、apple, banana, orange , melon という4つの要素をもつリストを fruitsという変数にセットしています。fruitsという名前のリストを作っているわけです。
リストのイメージ

- リストは、先頭から 0 番目、1 番目、2 番目と順番が振られていて、この順番を表す番号をインデックスといいます。
- リストは変数がつながったようなデータですが、その1つ1つを要素といいます。
- リストは普通、変数にセットして名前をつけます。
fruits = [ ‘apple’ , ‘banana’ , ‘orange’ ,’melon’ ]

# n 個の要素をもつリストを作り、変数にセットする
リストの変数 = [ 0番目の要素のデータ, 1 番目の要素のデータ,… , n-1 番目の要素のデータ ]
特に空のリストをつくるときは
# n 個の要素をもつリストを作り、変数にセットする
リストの変数 = [ ]
あるいは
リストの変数 = list()
とします。
月曜日から日曜日までの文字をもつリスト youbi を作るソース
| 1 | youbi = [ ‘月曜日’,‘火曜日’,‘水曜日’,‘木曜日’,‘金曜日’,‘土曜日’,‘日曜日’ ] |
|---|
1.2 リストの要素にアクセスする
リストのあとに [ ] でインデックスを指定します。そのインデックスの要素を得ることができます。
#あるリスト array の k 番目の要素を変数 x に代入する方法
x = array[k]
2 番目の要素’水曜日’を変数 wednesday に代入するソース( lecture007_01.py )
1 2 3 |
youbi = [ '月曜日','火曜日','水曜日','木曜日','金曜日','土曜日','日曜日' ] wednesday = youbi[2] print(wednesday) |
|---|
実行結果
| 1 | 水曜日 |
|---|
#あるリスト array の k 番目の要素を変数 x の中身で書き換える方法
array[k] = x
2番目の要素’水曜日’を「すいようび」に変更するソース( lecture007_02.py )
1 2 3 |
youbi = [ '月曜日','火曜日','水曜日','木曜日','金曜日','土曜日','日曜日' ] youbi[2] = 'すいようび' print(youbi[2]) |
|---|
実行結果
| 1 | すいようび |
|---|
1.3 リストへの要素の追加と削除
#あるリストの末尾に値あるいは、変数 x に入った値で要素を追加する方法
リストの変数名. append(x)
#あるリストのN番目の要素を削除する方法
リストの変数名. pop(N)
特に先頭を削除するのは
リストの変数名. pop(0)
N番目を削除すると、N+1番目がNになり、…と1個ずつずれていきます。
N番目のインデックスでなく要素を指定して削除する方法は、「時間があまったあなたに」を読んでください。他にもリストの発展的な操作を紹介しています。
右辺と左辺がないのが特徴です。
たとえば、要素が 3 つのリストに4つ目を更新する形で要素を追加できるかやってみましょう。
7 番目に要素「にちようび」を追加する( lecture007_03A.py )
1 2 3 |
youbi = [ ‘月曜日’,‘火曜日’,‘水曜日’,‘木曜日’,‘金曜日’,‘土曜日’,‘日曜日’ ] youbi[7]=’にちようび’ print(youbi[7]) |
|---|
実行結果(エラーになります。)
1 2 3 4 5 |
lecture007> python .\lecture007_03.py
Traceback (most recent call last):
File ".\lecture007_03.py", line 2, in module
youbi[7] = 'にちようび'
IndexError: list assignment index out of range
|
|---|
7 番目に要素「にちようび」を追加する( lecture007_03B.py )
1 2 3 4 5 |
youbi = [ '月曜日','火曜日','水曜日','木曜日','金曜日','土曜日','日曜日' ] new_e = 'にちようび' youbi.append(‘にちようび’) youbi.append(new_e) print(youbi[7]) |
|---|
実行結果(エラーにならずに正しく実行されます。)
| 1 | にちようび |
|---|
リスト全体を見てみましょう。
1 2 3 5 |
youbi = [ '月曜日','火曜日','水曜日','木曜日','金曜日','土曜日','日曜日' ] new_e = 'にちようび' youbi.append(new_e) print(youbi) |
|---|
実行結果
| 1 | [‘月曜日’, ‘火曜日’, ‘水曜日’, ‘木曜日’, ‘金曜日’, ‘土曜日’, ‘日曜日’, ‘にちようび’] |
|---|
最後に要素が増えていることがわかります。
1.4 リストを保持する変数にリストを代入する
リストの代入には注意が必要です。
突然ですが、下記のコードを実行してみましょう。hairetsu01 と hairetsu02 というリストがあり、hairetsu02 に hairetsu01 を代入しました。hairetsu02 の中身が hairetsu01 と同じになるのは理解できるでしょう。しかし、独立だと思われた hairetsu01 の中身を書き換えると、なんと hairetsu02 の中身も下記代わってしまうのです。
リストを=で代入する。(lecture007_04A.py)
1 2 3 4 5 6 7 |
hairetsu01 = ['りんご','バナナ','みかん','メロン'] hairetsu02 = ['apple','banana','orange','melon'] hairetsu02 = hairetsu01 print(hairetsu02) hairetsu01[3] = '梨' print(hairetsu02) |
|---|
実行結果( hairetsu01 の要素を書き換えると、hairetsu02 の要素も書き換わってしまう)
1 2 |
['りんご', 'バナナ', 'みかん', 'メロン'] ['りんご', 'バナナ', 'みかん', '梨'] |
|---|
一方、この hairetsu01 や hairetsu02 が文字だったらどうでしょうか。(lecture007_04B.py)
1 2 3 4 5 6 7 8 |
hairetsu01 = 'りんご' hairetsu02 = 'apple' hairetsu02 = hairetsu01 print(hairetsu02) hairetsu01 = '梨' print(hairetsu02) |
|---|
実行結果( hairetsu01 の要素を書き換えても、hairetsu02 の要素は書き換わらない)
1 2 |
りんご りんご |
|---|
hairetsu01, hairetsu02 の変数が文字列だと、影響は受けません。
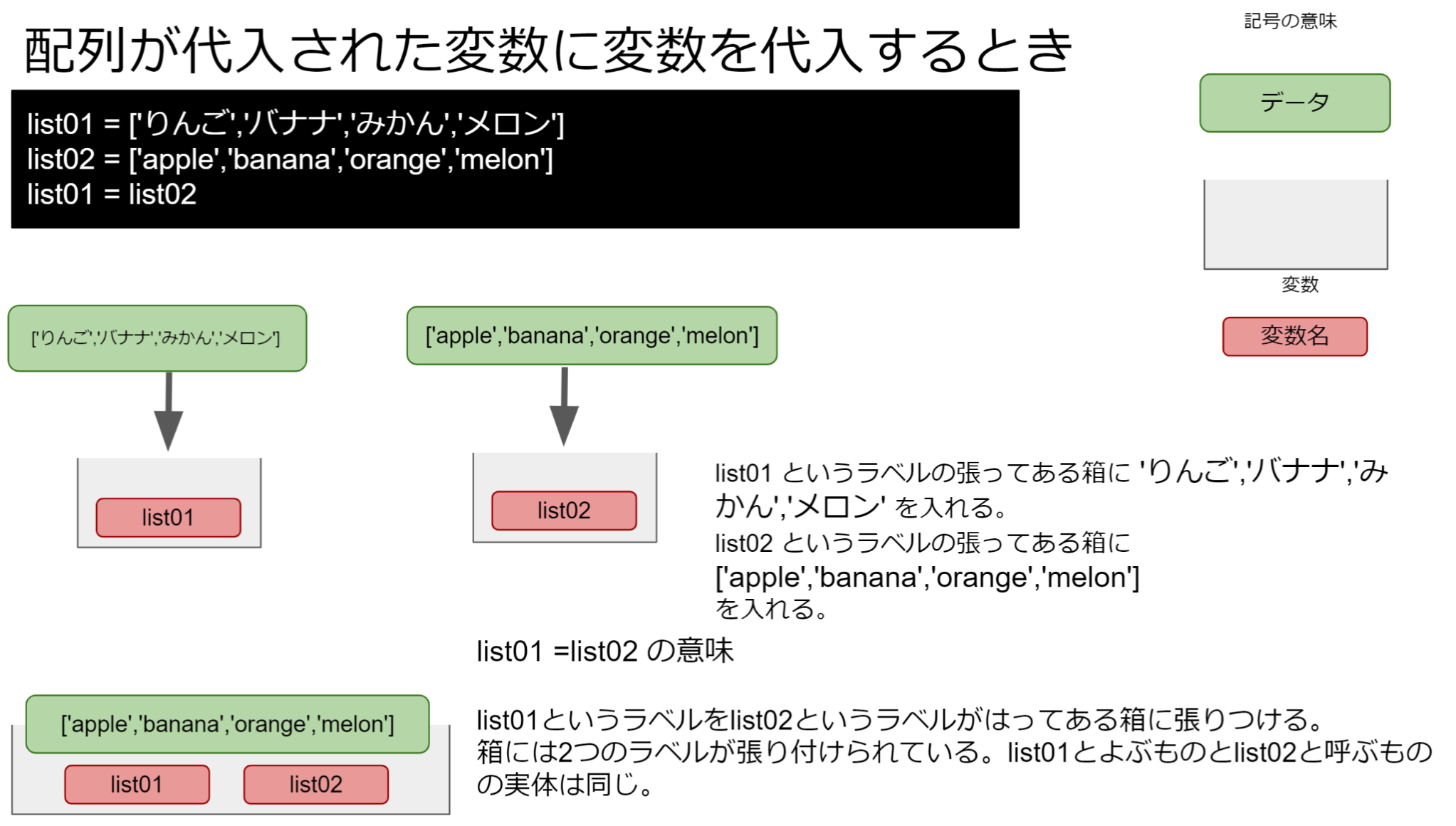
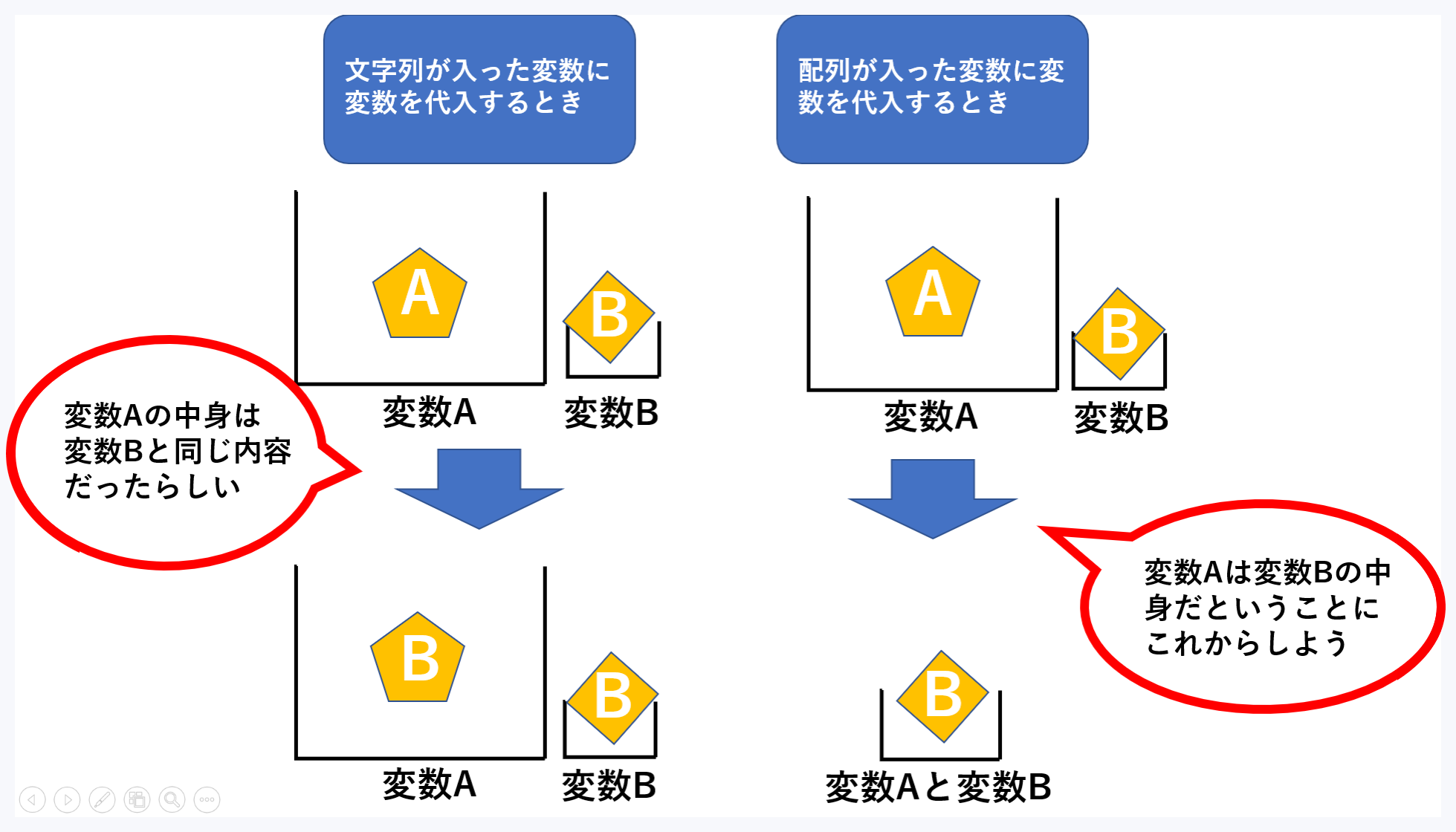
変数に文字列や数字を代入して、その 2 つの変数を統合するとき、2 つにはそれぞれ別のデータ(オブジェクト)が割り当てられます。
一方、リストでは、同じオブジェクトが割り当てられます。リストを使うときは変数に代入して名前を付けます。しかし、このリストを指し示す変数を = で結ぶときは注意が必要です。
1.5 リストをネストする
リストの要素はこれまで数字や文字列でしたが、リストの要素にリストを入れることもできます。つまり、リストをネストするわけです。
例えば、次のようなデータを見てみましょう。47 都道府県の都道府県名、男性の平均寿命、女性の平均寿命を表しています。
lecture007_07_1.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 41 43 44 45 46 47 48 49 |
ranking = [
['滋賀県','81.78','87.57'],
['長野県','81.75','87.67'],
['京都府','81.40','87.35'],
['奈良県','81.36','87.25'],
['神奈川県','81.32','87.24'],
['福井県','81.27','87.54'],
['熊本県','81.22','87.49'],
['愛知県','81.10','86.86'],
['広島県','81.08','87.33'],
['大分県','81.08','87.31'],
['東京都','81.07','87.26'],
['石川県','81.04','87.28'],
['岡山県','81.03','87.67'],
['岐阜県','81.00','86.82'],
['宮城県','80.99','87.16'],
['千葉県','80.96','86.91'],
['静岡県','80.95','87.10'],
['兵庫県','80.92','87.07'],
['三重県','80.86','86.99'],
['山梨県','80.85','87.22'],
['香川県','80.85','87.21'],
['埼玉県','80.82','86.66'],
['島根県','80.79','87.64'],
['新潟県','80.69','87.32'],
['福岡県','80.66','87.14'],
['佐賀県','80.65','87.12'],
['群馬県','80.61','86.84'],
['富山県','80.61','87.42'],
['山形県','80.52','86.96'],
['山口県','80.51','86.88'],
['長崎県','80.38','86.97'],
['宮崎県','80.34','87.12'],
['徳島県','80.32','86.66'],
['北海道','80.28','86.77'],
['茨城県','80.28','86.33'],
['沖縄県','80.27','87.44'],
['高知県','80.26','87.01'],
['大阪府','80.23','86.73'],
['鳥取県','80.17','87.27'],
['愛媛県','80.16','86.82'],
['福島県','80.12','86.40'],
['栃木県','80.10','86.24'],
['鹿児島県','80.02','86.78'],
['和歌山県','79.94','86.47'],
['岩手県','79.86','86.44'],
['秋田県','79.51','86.38'],
['青森県','78.67','85.93'],
]
|
|---|
0 番目は滋賀県で、1 番目は長野県のデータです。
データは以下で取り出せます。
変数 = リスト名[外側のリストとしてのインデックス][ネストされたリストのインデックス]
例えば、京都府の女性の平均寿命は、次のようにして代入できます。
| 1 | kyoto_female = ranking[2][2] #87.35 |
|---|
さらに代入するときは、
| 1 | ranking[2][2] = 90.11 |
|---|
のようにして値を書き換えることができます。
1.6 文字列からリストを作成する。
こんな場面を考えてみましょう。花子さんは、毎日朝顔の背丈を調べて平均と一番大きい背丈と一番小さい背丈のものの差を記録しています。これを毎日電卓でなく、プログラムで計算させたいと思っています。
毎日の朝顔の背丈平均プログラム(青い文字はキーボードから入力)
4つの朝顔の今朝の背丈を小さい順に、cmで入力してください。4つはスペースで区切ってください。
3.8 4.2 4.3 4.5
平均は 4.2 です。
一番小さい株と一番大きい株との差は 0.7cm です。
入力は、半角スペース 1 つで 4 つの数字を区切った文字列になります。
次のようにすると、この「3.8 4.2 4.3 4.5」の1行の入力をスペースで分割し、4つの数字として要素を持つリストにすることができます。
スペースで区切った文字列からリストを作る。(lecture007_05.py)
1 2 3 4 |
print("4つの朝顔の今朝の背丈を小さい順に、cmで入力してください。4つはスペースで区切ってください")
setake_4 = input()
setake = setake_4.split(' ')
print(setake)
|
|---|
実行結果
1 2 3 4 |
ecture007> python .\lecture007_05.py 4つの朝顔の今朝の背丈を小さい順に、cmで入力してください。4つはスペースで区切ってください 1 2 3 4 ['1', '2', '3', '4'] |
|---|
すなわち、split 関数は、以下のようにして文字列を区切り文字で分割し、リストにできます。
リストを格納する変数 = 分割したい文字列 . split(区切り文字列)
例えば、分割したい文字列があって、それが”北海道 – 青森 – 沖縄 – 香川”としましょう。区切り文字は – です。( lecture007_07.py )
1 2 3 |
todofuken = "北海道 - 青森 - 沖縄 - 香川"
ken_4 = todofuken.split(' - ')
print(ken_4)
|
|---|
実行結果
| 1 | [‘北海道’, ‘青森’, ‘沖縄’, ‘香川’] |
|---|
演習の時間
演習の解答はここからダウンロードできます。ダウンロードfile_download
演習1
歴代の総理大臣の名前を検索する簡単な名前検索システムを作ってみましょう。歴代総理大臣のデータは先生から受け取ってください。president というリストです。このリストは、第 N 代総理大臣の名前がこのリストの N 番目の要素になっています。なお第 0 代総理大臣というのはいないので空欄になっています。enshu007_01.py の名前で保存しましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
president = [
"",
"伊藤博文",
"黒田清隆",
"山縣有朋",
"松方正義",
"伊藤博文",
"松方正義",
"伊藤博文",
"大隈重信",
"山縣有朋",
# ・・・(中略。実際のソースコードには書かれています。)・・・
"福田康夫",
"麻生太郎",
"鳩山由紀夫",
"菅直人",
"野田佳彦",
"安倍晋三",
"安倍晋三",
"安倍晋三"
]
|
|---|
このリストを使って、第 N 代総理大臣の名前を表示するプログラムを作ってみましょう。
ヒント
そのリストのインデックスの番号が総理大臣の N 代目を表しています。N 番目の要素の値はどのようにして取得していたでしょうか。
期待される動作
第何代総理大臣の名前を調べますか?
69
第69代総理大臣は
大平正芳
です
【演習2】
lecture007_07_1.py の 47 都道府県の平均寿命のデータを使って、男性と女性の平均寿命の差が一番大きい都道府県を調べてみましょう。enshu007_02.py の名前で保存しましょう。
1 2 3 |
ranking =[
['滋賀県','81.78','87.57'],
['長野県','81.75','87.67'],…
|
|---|
期待される動作
男女差が一番大きいのは7.26歳で□□県です
【演習3】
A子さんは、朝顔のタネを 5 粒別々の鉢に撒いて、5 の個体の個体差を調べています。毎日、苗の背丈の記録をとり、平均、最大と最小の差などを記録につけています。
A子さん用に、平均 と 最大ー最小 を計算するプログラムを書いてください。
期待される動作
5 つの苗の背丈(単位 cm )を半角スペースで区切って入力してください。
2.5 2.4 2.1 2.8 2.9
平均は、25.4 cm 、 最大背丈と最小背丈の差は 0.4 cm でした。
ヒント
リストの中で最大のものを返す関数は max ,最小のものを返す関数は min です。
例えば print(max([10, 20, 30, 20, 5, 3])) は 30 になります。
時間があまったあなたに
様々なリストの操作をみてみよう
リストには様々な操作が用意されています。
fruits =[‘apple’ , ‘orange’ , ‘banana’] を使って説明します。
N 番目のインデックスを削除するとき
del リストの変数名[N]
1 2 3 |
fruits =['apple' , 'orange' , 'banana'] del fruits[1] print(fruits)#['apple' , 'banana']になる |
|---|
これは注意です。他の操作は、リストの変数名.なんとか の形をしています。リストの変数名.del(N) でないことに注意です。(実は、del は関数でなく、文と呼ばれます)
要素の中身を指定して削除するとき
リストの変数名.remove(要素の値)
1 2 3 |
fruits =['apple' , 'orange' , 'banana']
fruits.remove('orange')
print(fruits) #['apple' , 'banana']になる
|
|---|
N 番目のインデックスの要素の削除し、別の変数に入れる
N番目の要素= リストの変数名.pop(N)
1 2 3 4 |
fruits =['apple' , 'orange' , 'banana'] fr = fruits.pop(1) print(fr)# i\orange print(fruits) #['apple' , 'banana']になる |
|---|
リストを空にするとき
リストの変数名.clear()
リストの変数名 = [] と同じです。
1 2 3 |
fruits =['apple' , 'orange' , 'banana'] fruits.clear() print(fruits) #[]になる |
|---|
大人のあなたへ
オブジェクト指向プログラミングとメソッド
今まで関数は、下記のようにして使いました。
関数が返す値を代入する変数 = 関数名(引数、引数、…)
例えば文字列の長さを調べる関数 len は
| 1 | moji_nagasa = len(”この文字な何文字かな?”) |
|---|
のように使いました。
しかし、今回、リストに様子を追加する append は
| 1 | list_name.append(“追加する文字”) |
|---|
のように使います。
| 1 | list_name = append(list_name,“追加する文字”) |
|---|
ではありません。これはappend は関数のようなものですが、正確には違います。メソッドというものです。リストはオブジェクトというものの1つですが、
オブジェクトには、
オブジェクト . そのオブジェクトに対する操作(その操作の引数)
のようにして操作を行います。
このようなプログラミング方法、あるいはプログラミングスタイルをオブジェクト指向プログラミング(OOPと略します。)と言います。
オブジェクトに対する操作はこれまで関数という言い方をしてきましたが、オブジェクト指向プログラミングでは、関数に相当するものをメソッドと言います。
今は、文字列や数字には今までのような関数を使い、オブジェクトには関数の代わりにメソッドを使う、そしてメソッドはオブジェクトとメソッドをピリオドで結ぶということを覚えておいてください。